


Google vừa nâng cấp Veo – nền tảng tạo video bằng AI – với phiên bản Veo 3, cho phép bạn tạo ra đoạn video chất lượng cao kèm âm thanh bao gồm hiệu ứng môi trường, tiếng nhân vật, và lời thoại — tất cả đều được phát trực tiếp từ AI 🎬.
🎯 Veo 3 là gì?
- Video hỗ trợ AI thế hệ thứ 3 của Google DeepMind, mang khả năng text‑to‑video và lần đầu tiên là video + audio đồng bộ .
- Có thể tạo clip 8 giây, 720p, 24fps, bằng prompt chứa mô tả cảnh và lời thoại
📌 Xem thêm:
👉 🌸 Google Veo - AI làm phim có âm thanh tích hợp
👉 🔓 Hướng dẫn đăng ký và sử dụng Veo 3 không cần VPN
🌍 Hướng dẫn truy cập Google Flow và tạo video có giọng nói bằng Veo 3
🚀 Phần 1: Cách truy cập giao diện Flow của Google
Để sử dụng tính năng "Tạo video từ hình ảnh có giọng nói" trên Veo 3, bạn cần truy cập vào giao diện Flow của Google và đổi địa chỉ IP sang quốc gia được hỗ trợ (như Hoa Kỳ). Cách thực hiện như sau:
✅ Bước 1: Cài đặt VPN để đổi IP
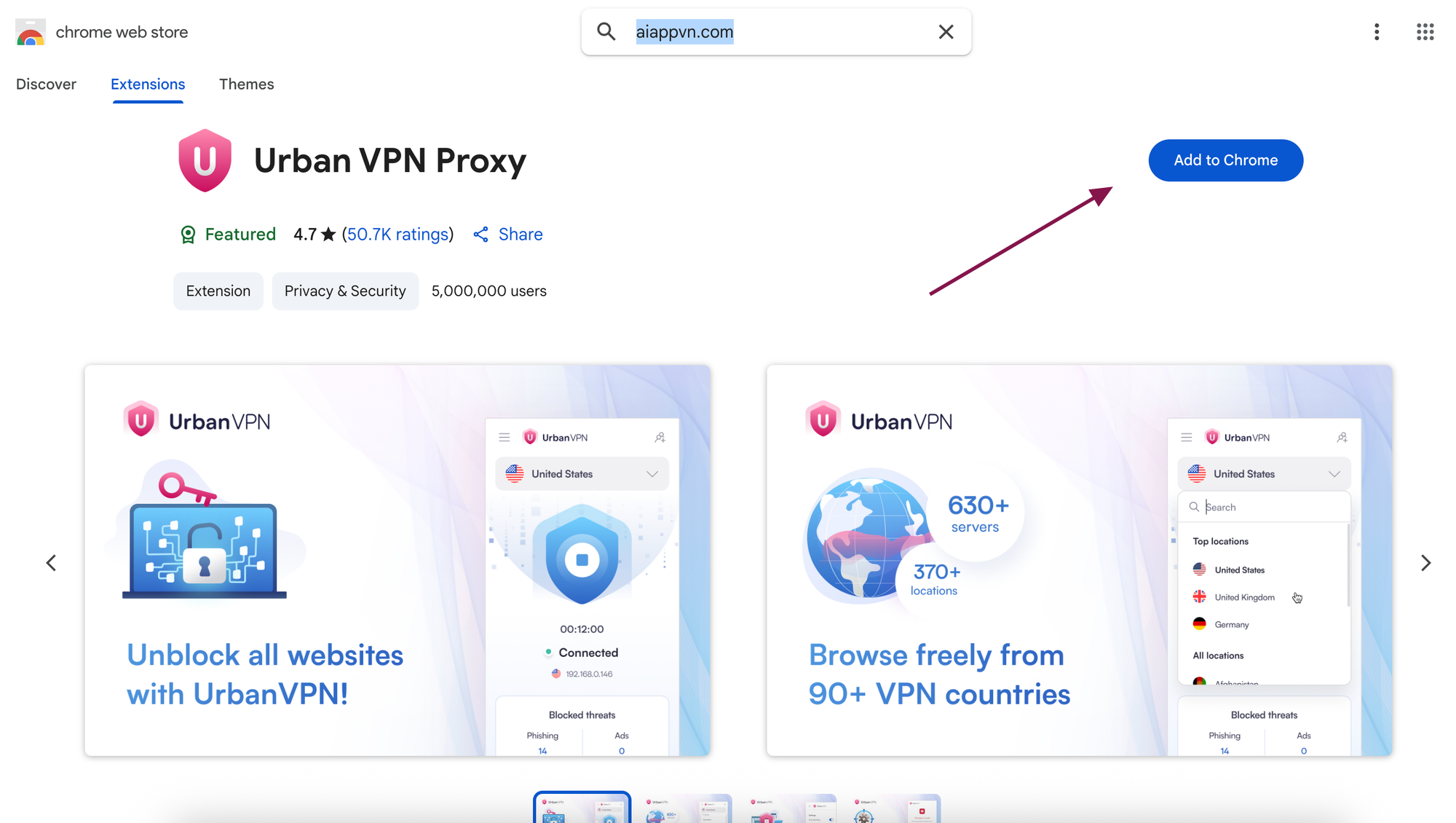
- Truy cập Chrome Web Store, tìm tiện ích "VPN Urban Proxy"
- Nhấn "Thêm vào Chrome" > "Thêm tiện ích"
✅ Bước 2: Kích hoạt VPN
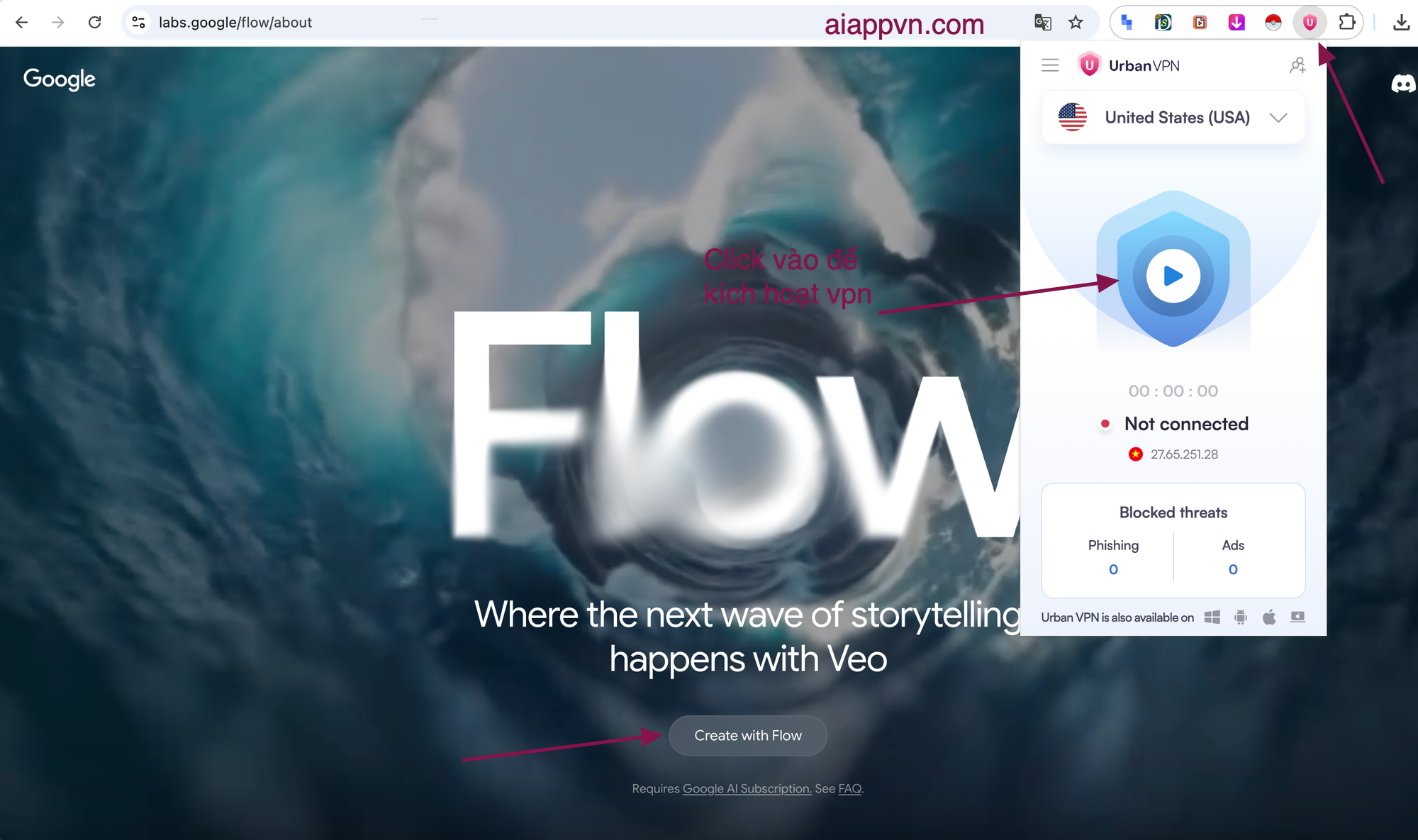
- Nhấn vào biểu tượng tiện ích VPN trên trình duyệt
- Chọn quốc gia United States (USA) và kích hoạt
- Khi thấy đồng hồ đếm thời gian chạy, tức là VPN đã hoạt động thành công
✅ Bước 3: Truy cập Google Flow
- Truy cập: https://labs.google
- Chọn "Try in Flow" > "Create with Flow"
✅ Bước 4: Đăng nhập và bắt đầu
- Đăng nhập tài khoản Google có đăng ký gói Pro hoặc Ultra của Veo 3

- Tạo "New Project" để bắt đầu sử dụng công cụ tạo video
🎬 Phần 2: Tạo video từ hình ảnh có giọng nói với Veo 3
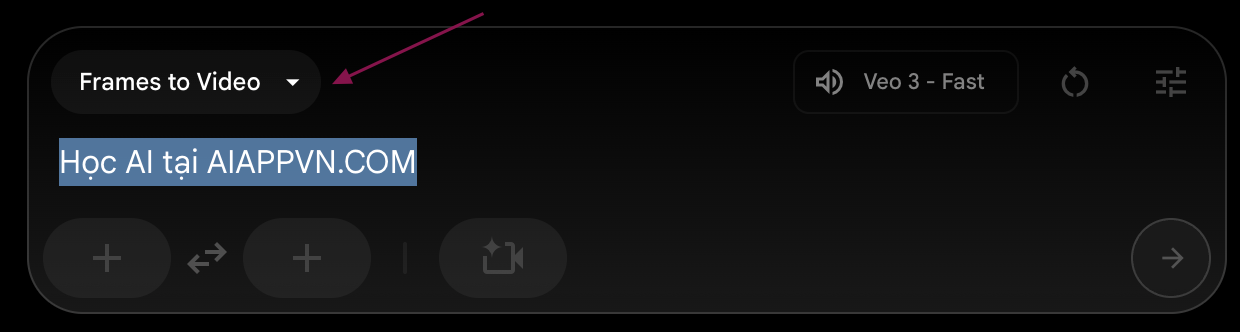
✅ Bước 1: Chọn tính năng "Frames to Video"
- Trong giao diện Flow, chọn tính năng "Tạo video từ khung hình đầu tiên" (first-frame)
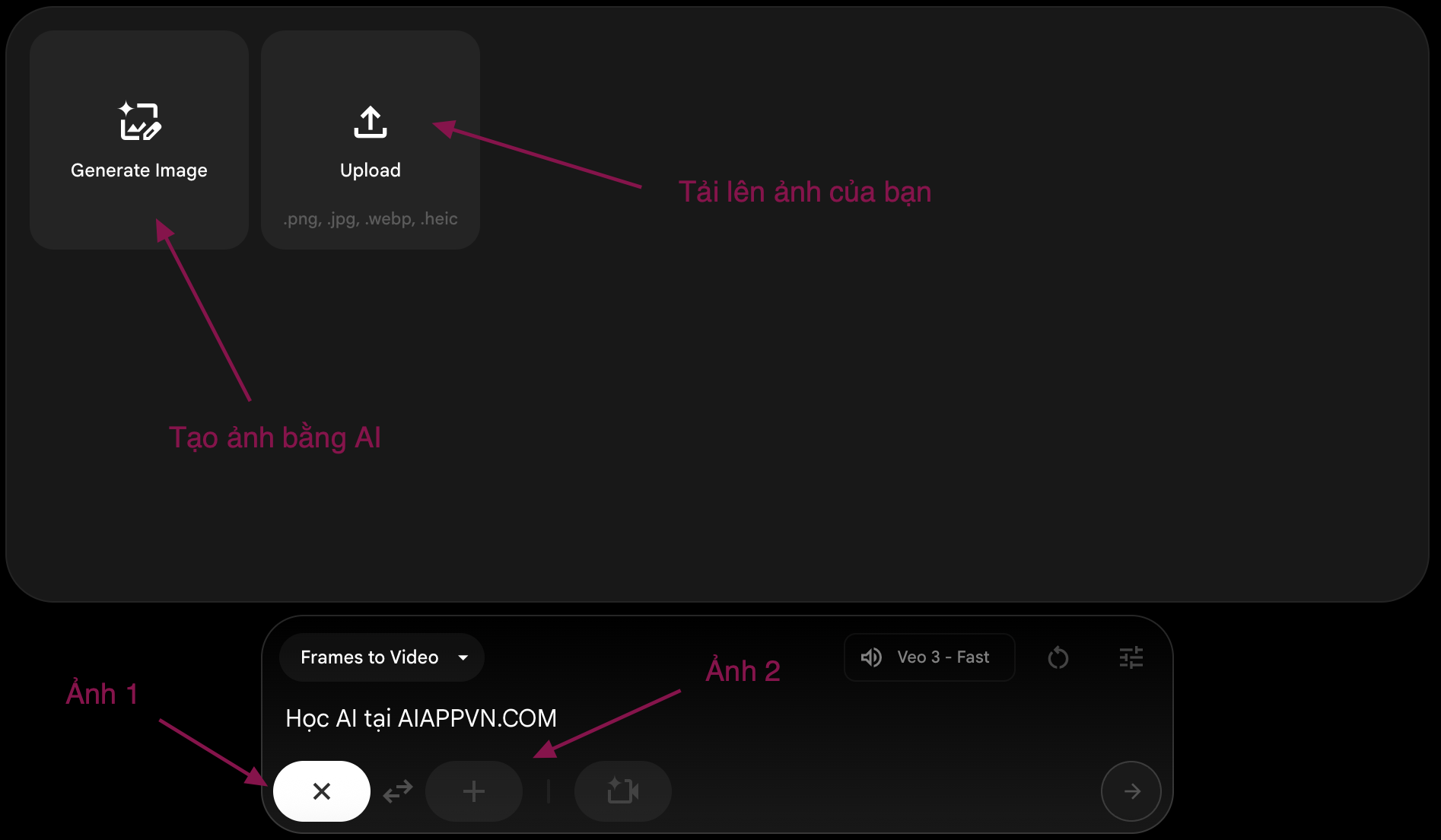
✅ Bước 2: Tải ảnh lên
- Click biểu tượng "+" để tải 1 hoặc 2 hình ảnh
- 1 ảnh = video tĩnh
- 2 ảnh = hiệu ứng chuyển cảnh (ảnh đầu và ảnh cuối)
📌 Lưu ý:
💡
Veo 3 hiện đã hỗ trợ hình ảnh người thật, kể cả ảnh chụp từ máy ảnh hoặc điện thoại.
- Tuỳ nhiên bạn nên sử dụng các công cụ AI như Midjourney, Ideogram, hoặc DALL·E để tạo hình minh họa hoặc nhân vật hoạt hình, cartoon.
- Bạn cũng có thể thực hiện các bước chuyển đổi image-to-image để biến đổi ảnh nhưng vẫn sẽ giữ được dáng và biểu cảm, nhưng không còn là người thật.
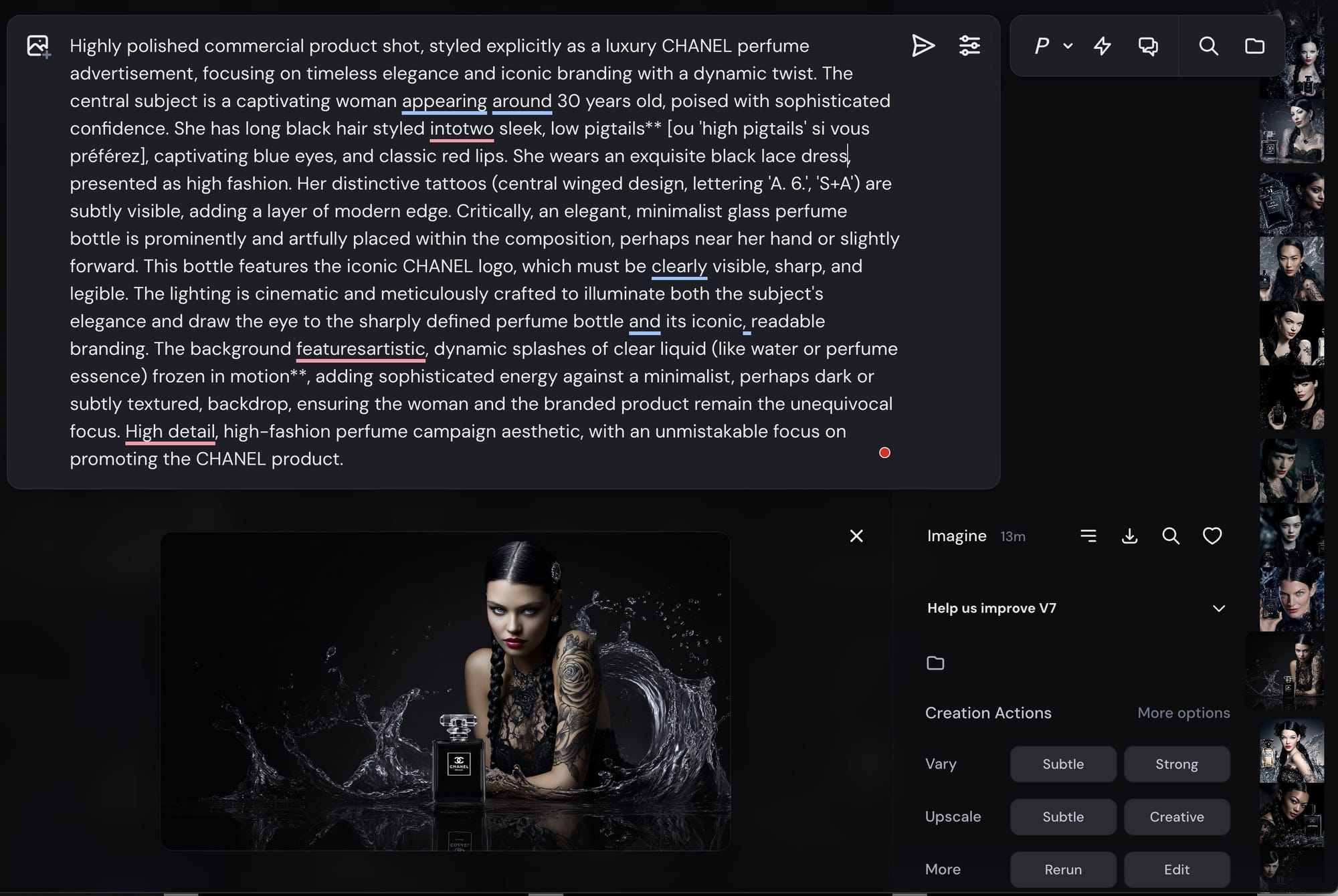
✅ Bước 3: Nhập prompt mô tả video
- Mô tả cảnh quay, hành động, biểu cảm, môi trường, v.v.
- Prompt nên sử dụng tiếng Anh.
- Bạn có thể sử dụng các công cụ như ChatGPT, Grok, Gemini để tạo promp
- Tuy nhiên, bạn có thể chèn lời thoại ở bất kỳ ngôn ngữ nào. Xem ví dụ:
🎯 Mẫu prompt:
A young Vietnamese girl walks through a rainy alley in Hanoi. She looks at the sky and says in Vietnamese: "Trời mưa mà vẫn đẹp ghê."
💡
Âm thanh hiện vẫn đang ở giai đoạn thử nghiệm (beta), do đó có trường hợp video được tạo ra nhưng không có tiếng, hoặc giọng bị ngắt quãng.
Nếu làm nhiều video liên tiếp với cùng nhân vật, giọng nói dễ bị thay đổi hoặc không khớp, khiến trải nghiệm xem không liền mạch.
Nếu làm nhiều video liên tiếp với cùng nhân vật, giọng nói dễ bị thay đổi hoặc không khớp, khiến trải nghiệm xem không liền mạch.
Một số cách khắc phục bằng cách: dùng ElevenLabs, TTSMaker để tạo giọng riêng, rồi ghép vào video bằng phần mềm dựng phim như Premiere hoặc CapCut.
✅ Bước 4: Tạo video
- Sau khi nhập prompt và tải ảnh xong, nhấn biểu tượng → "Generate"
- Chọn chế độ:
- Veo 3 Fast: nhanh, rẻ (20 credits), nhưng không hỗ trợ giọng nói và thường không ổn định
- Veo 3 Quality: tốn 100 credits, chất lượng hình ảnh và âm thanh tốt hơn, có hỗ trợ giọng nói

✅ Bước 5: Tải video về
- Nhấn biểu tượng📥 "Download", chọn độ phân giải 1080p để có chất lượng tốt nhất
⚠️ Các lưu ý quan trọng
- Giọng nói (audio) hiện chỉ hỗ trợ ở chế độ Veo 3 Quality và đang ở giai đoạn thử nghiệm (beta)
- Không phải video nào cũng có âm thanh — hãy thử nhiều prompt khác nhau nếu cần
- Mỗi video hiện chỉ dài tối đa 8 giây
- Không sử dụng hình ảnh, giọng nói hoặc nội dung vi phạm bản quyền
🌟 Gợi ý quy trình chuyên nghiệp (workflow đề xuất)
- Tạo nhân vật hoạt hình bằng Midjourney hoặc DALL·E
- Dùng Google Flow - Veo 3 Quality để tạo video hoạt cảnh + thoại
- Sử dụng ElevenLabs để lồng giọng chuyên nghiệp và nhất quán
- Dựng video bằng CapCut hoặc Premiere Pro để nối nhiều đoạn thành 1 clip hoàn chỉnh
🍁
Liên hệ chúng tôi tại support@aiappvn.com nếu bạn cần hỗ trợ
💞
Đăng ký thành viên để xem những phản hồi của người dùng và để lại comment 💬 về trải nghiệm ứng dụng nếu bạn đã sử dụng cho cộng đồng biết nhé. 👇 Click vào thẻ tag phía dưới để xem những ứng dụng liên quan.


