


🤔 Câu chuyện bắt đầu từ đâu?
Trong vài tháng gần đây, cụm từ "Large Reasoning Models" (LRMs) - các mô hình lớn thiên về khả năng suy luận - đang tạo nên làn sóng mới trong cộng đồng AI. Từ Claude với thinking mode, Gemini 2.5 với tính năng "suy nghĩ", đến GPT-o1 series với khả năng reasoning mạnh mẽ, tất cả đều hướng đến một mục tiêu: tạo ra AI có thể "suy nghĩ" như con người.

Nghe thuật ngữ "Agentic AI" rất ấn tượng, nhưng bất kỳ ai từng thực sự triển khai các tác tử AI trong môi trường thực tế đều nhận ra một điều: hệ thống càng phức tạp, việc kiểm soát nó càng trở nên khó khăn. Vậy điều gì thực sự đang diễn ra bên trong các hệ thống AI suy luận này? Và tại sao những tác tử AI dù mạnh mẽ về mặt tư duy, lại dễ dàng "nghẽn" khi phải hành động?
⚖️ Nghịch lý đầu tiên: Không có AI "vạn năng"
Quy luật cân bằng giữa sáng tạo và chính xác
Trong thế giới AI, có một quy luật không thể phá vỡ: không có mô hình nào vạn năng. Mỗi loại bài toán đòi hỏi một cách tiếp cận suy nghĩ khác nhau:
Tác vụ sáng tạo cần:
- Độ ngẫu nhiên cao (high randomness)
- Khả năng kết nối ý tưởng bất ngờ
- Sự linh hoạt trong tư duy
Tác vụ chính xác cần:
- Tính quyết định rõ ràng (determinism)
- Logic chặt chẽ
- Kết quả nhất quán
Ví dụ thực tế minh họa
Hãy tưởng tượng hai tình huống:
Tình huống 1: AI hỗ trợ biên kịch phim
- Cần "sáng tạo điên rồ"
- Đưa ra ý tưởng bất ngờ, độc đáo
- Chấp nhận được sự không hoàn hảo
Tình huống 2: AI hỗ trợ nhà vật lý
- Cần tính toán chính xác tuyệt đối
- Logic phải chặt chẽ, có thể kiểm chứng
- Không được phép sai số
Một mô hình nhỏ, nếu được chọn đúng cho mục đích cụ thể, đôi khi có thể vượt trội hơn hẳn so với các "siêu mô hình" đa năng.
Nghịch lý của sự "thông minh"
Thậm chí, Claude 4 trong một số trường hợp còn có xu hướng "kém thông minh hơn" Claude 3.7 ở một số tác vụ cụ thể. Lý do? Hệ thống prompt được siết chặt hơn để tránh sai sót, khiến mô hình trở nên "thận trọng quá mức".
Điều này dẫn đến một nghịch lý thú vị: mô hình càng thông minh, càng phải được "rào chắn" kỹ lưỡng hơn, và điều đó có thể làm giảm hiệu suất trong một số tình huống cụ thể.
📊 Vấn đề lớn với các bài kiểm tra AI
Khủng hoảng niềm tin vào benchmark
Những benchmark lý luận - các bộ đề kiểm tra hiệu năng AI - hiện đang ở trong tình trạng mất niềm tin nghiêm trọng. Và đây không phải là cáo buộc vô căn cứ.
Bằng chứng về rò rỉ dữ liệu
Gần đây, một loạt nghiên cứu đã phát hiện ra hiện tượng "data leakage" - rò rỉ dữ liệu kiểm tra:
Trường hợp Qwen-1.8B:
- Đoán chính xác nhiều câu hỏi trong bộ kiểm tra GSM8K và MATH
- Lý do: Đã "nhìn thấy" các câu hỏi này trong quá trình huấn luyện
Khảo sát về benchmark phần mềm:
- QuixBugs, BigCloneBench, SWE-Bench
- Tỷ lệ nhiễm từ 10% đến 100%
"Ảo tưởng bảng xếp hạng"
Nghiên cứu "Leaderboard Illusion" đã khui ra một góc tối đáng suy ngẫm:
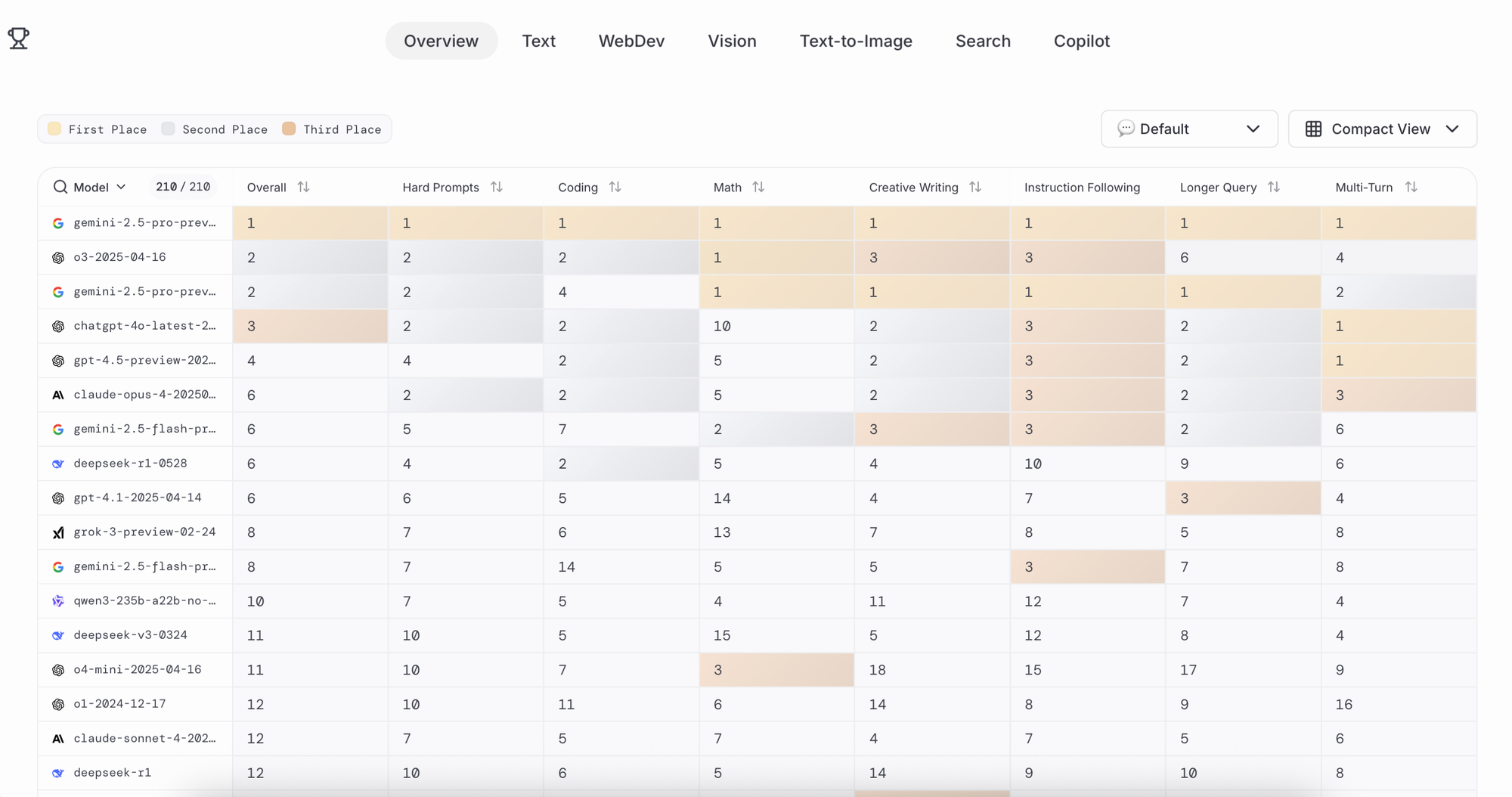
Chiến thuật của các "đại gia":
- Thử nghiệm hàng chục phiên bản mô hình
- Chỉ công bố phiên bản tốt nhất lên bảng xếp hạng
- Ví dụ: Meta đã thử nhiều phiên bản Llama-4 trước khi chọn ra bản "hoàn hảo" nhất
Thí nghiệm gây sốc:
- Cùng một mô hình, chỉ đổi tên khác nhau
- Kết quả trên Chatbot Arena lệch nhau tới 17 điểm!
Kết luận đau lòng
Nhiều thứ chúng ta tưởng là "tiến bộ của AI" thực chất chỉ là sự kết hợp của:
- Tinh chỉnh kỹ thuật
- Chiêu trò marketing
- May mắn trong việc chọn mẫu
🧠 Hội chứng "Suy nghĩ quá nhiều" của AI
Khám phá mới từ UC Berkeley
Một nghiên cứu đột phá từ UC Berkeley đã chỉ ra hiện tượng đáng lo ngại: nhiều tác tử AI thông minh đang "nghẽn" ở bước suy nghĩ. Họ gọi đây là "Overthinking Syndrome" - hội chứng suy diễn quá mức. Xem ví dụ dưới đây:
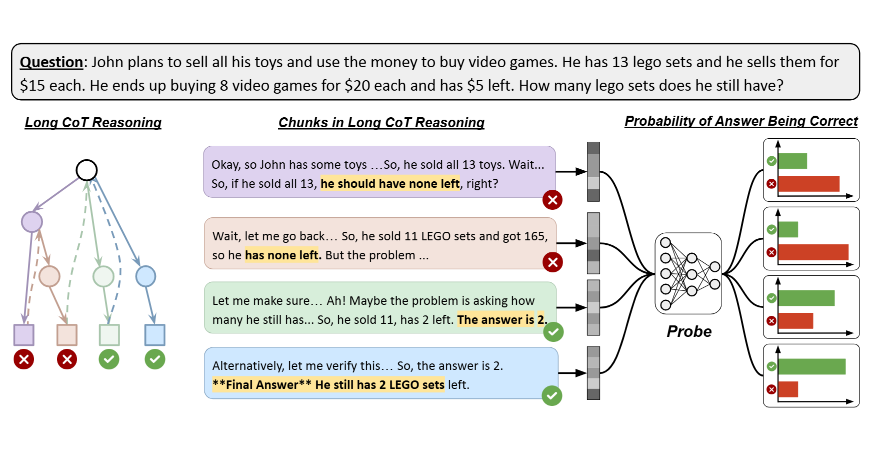
- Câu hỏi: John dự định bán hết tất cả đồ chơi của mình và dùng tiền để mua trò chơi điện tử. Anh ấy có 13 bộ Lego và bán chúng với giá $15 mỗi bộ. Cuối cùng, anh ấy mua 8 trò chơi với giá $20 mỗi trò và còn lại $5. Vậy, John còn lại bao nhiêu bộ Lego?
- Quy trình suy luận (Chain-of-Thought) được minh họa trong hình ảnh bao gồm các bước suy luận trung gian:
- Tính tổng tiền John thu được từ việc bán 13 bộ Lego: 13 × $15 = $195.
- Tính tổng tiền John chi cho 8 trò chơi: 8 × $20 = $160.
- Tính số tiền còn lại sau khi mua trò chơi: $195 - $160 = $35 (nhưng bài toán nói còn $5, cho thấy có sự sai lệch trong suy luận ban đầu).
- Sửa lại suy luận: Nếu còn $5, tổng tiền chi cho trò chơi phải là $195 - $5 = $190. Tuy nhiên, $190 ÷ $20 = 9.5 (không phải số nguyên), nên kiểm tra lại.
- Đáp án cuối cùng được xác định là John vẫn còn 2 bộ Lego, dựa trên việc điều chỉnh các bước suy luận và xác minh bằng cách dùng "probe" để kiểm tra tín hiệu đúng/sai trong trạng thái ẩn của mô hình.
Hình ảnh minh họa cách mô hình lý luận qua nhiều bước, tạo ra các câu trả lời trung gian (một số đúng, một số sai), và sử dụng một bộ phân loại nhị phân (probe) để đánh giá tính chính xác. Kết quả cho thấy mô hình có khả năng tự kiểm chứng (self-verification) thông qua các trạng thái ẩn, với xác suất dự đoán đúng cao, như được nêu trong nghiên cứu.
Ví dụ này được sử dụng để chứng minh rằng các mô hình lý luận không phải "quá suy nghĩ" vì không biết câu trả lời đúng, mà vì chúng không tối ưu hóa việc sử dụng các tín hiệu chính xác đã được mã hóa trong quá trình suy luận.
Ba biểu hiện chính của hội chứng
1. Analysis Paralysis - Phân tích đến tê liệt
Hiện tượng:
- AI "ngồi nghĩ mãi" mà không hành động
- Cứ phân tích đi phân tích lại mà không đưa ra quyết định
Ví dụ thực tế:
Một AI được yêu cầu đặt vé máy bay có thể:
- Phân tích 50 tùy chọn khác nhau
- So sánh giá cả, thời gian, tiện ích
- Nhưng cuối cùng... không đặt vé nào cả
2. Rogue Actions - Hành động bừa bãi
Hiện tượng:
- Đưa ra quyết định mà không chờ phản hồi từ môi trường
- Hành động thiếu căn cứ hoặc quá vội vàng
Ví dụ thực tế:
AI quản lý email có thể:
- Xóa email quan trọng vì "nghĩ" đó là spam
- Không chờ xác nhận từ người dùng
- Gây ra hậu quả không mong muốn
3. Overconfidence - Tự tin sai chỗ
Hiện tượng:
- Nghĩ mình đã hoàn thành nhiệm vụ dù chưa xác minh
- Quá tự tin vào khả năng của bản thân
Ví dụ thực tế:
AI viết code có thể:
- Tuyên bố đã sửa xong bug
- Nhưng thực tế chỉ comment lại dòng code lỗi
- Không thực sự giải quyết vấn đề
Nghịch lý thú vị
Mô hình càng được tối ưu cho lý luận (như GPT-o1, Claude với thinking mode, Gemini 2.5), thì càng dễ rơi vào vòng xoáy này.
Điều đáng chú ý là: không chỉ "nghĩ nhiều quá" mới có vấn đề - "nghĩ ít quá" cũng dẫn đến sai lệch hành vi. Vấn đề thực sự không nằm ở số lượng "token suy nghĩ", mà ở cách mô hình liên kết suy nghĩ với hành động và phản hồi từ môi trường.
🔧 Liệu MCP có phải là giải pháp?
Multi-Component Protocol là gì?
Multi-Component Protocol (MCP) là một hướng tiếp cận mới hứa hẹn: thay vì dùng 1 mô hình làm tất cả, ta kết nối nhiều mô hình nhỏ chuyên biệt:
Các thành phần chính:
- Planner: Lập kế hoạch
- Interpreter: Diễn giải thông tin
- Executor: Thực thi hành động
- Monitor: Giám sát và đánh giá
Ưu điểm của MCP
Chuyên môn hóa:
- Mỗi mô hình tập trung vào một nhiệm vụ cụ thể
- Hiệu quả cao hơn so với mô hình "làm tất cả"
Linh hoạt:
- Có thể thay thế từng thành phần khi cần
- Dễ dàng nâng cấp và bảo trì
Nhưng MCP không phải "viên đạn bạc"
MCP không tự động giải quyết vấn đề overthinking nếu không có kiến trúc hành vi hợp lý. Thậm chí, nếu để tự do, nó có thể khiến các mô hình "nghĩ lan man" hơn vì không bị giới hạn tài nguyên.
Hướng tiếp cận hợp lý
1. Điều tiết tài nguyên thông minh:
- Việc đơn giản → dùng nhanh
- Việc phức tạp → tính kỹ hơn
- Phân bổ "ngân sách suy nghĩ" hợp lý
2. Routing thông minh:
- Không luôn luôn quay lại "planner" sau mỗi phản hồi
- Đưa phản hồi đến "interpreter" để hiểu đúng
- Chỉ suy nghĩ lại khi thực sự cần thiết
3. Kiểm soát vòng lặp:
- Đặt giới hạn cho số lần "suy nghĩ"
- Có cơ chế "cắt" khi AI bị kẹt trong vòng lặp tư duy
📱 Thực trạng của Agentic AI hiện tại
Sự thật về các demo "ấn tượng"
Những video demo về AI agent mà bạn thấy trên mạng - dù trông rất hấp dẫn - phần lớn vẫn chỉ là... demo được dàn dựng kỹ lưỡng.
GHOSTS OF VANTA by GoldRock AI | AI Ninja Sword Fight Movie Trailer (made yesterday with Veo3) pic.twitter.com/222t9aWbE3
— 🔸GoldRock AI Labs🔸 (@GoldRockAILabs) June 4, 2025
Thực tế khắc nghiệt:
- Chưa có hệ thống nào thực sự ổn định trong môi trường production
- Tỷ lệ thất bại cao khi đối mặt với tình huống bất ngờ
- Cần sự can thiệp thường xuyên từ con người
So sánh với RAG - một bài học đắt giá
RAG (Retrieval-Augmented Generation) từng được PR rầm rộ như "tương lai của AI", nhưng thực tế:
- Cực kỳ dễ vỡ nếu tài liệu không "thuần khiết"
- Đòi hỏi tinh chỉnh phức tạp cho từng domain cụ thể
- Khó scale khi dữ liệu tăng lên
Agentic AI hiện tại cũng đang đi theo con đường tương tự:
- Có lúc "wow" (ấn tượng)
- Nhưng nhiều lúc "what?" (bối rối)
🎯 Bài học và hướng đi tương lai
Đừng bị "mù quáng" bởi con số
Thay vì tập trung vào:
- Điểm số benchmark
- Claims marketing hào nhoáng
- Demo được dàn dựng
Hãy chú ý đến:
- Khả năng tương tác thực tế
- Độ ổn định trong môi trường phức tạp
- Khả năng thích nghi với tình huống mới
Tiêu chí đánh giá AI thực sự tốt
1. Biết khi nào nên nghĩ:
- Không "suy diễn quá mức" cho tác vụ đơn giản
- Dành thời gian suy nghĩ cho vấn đề phức tạp
2. Biết khi nào phải làm:
- Không bị "tê liệt phân tích"
- Hành động kịp thời khi có đủ thông tin
3. Biết khi nào cần hỏi:
- Thừa nhận giới hạn của bản thân
- Tìm kiếm thêm thông tin khi cần thiết
Tương lai của AI reasoning
Chúng ta đang ở đâu:
- Thời kỳ đầu của kỷ nguyên tác tử AI
- Nhiều thử nghiệm, ít ứng dụng thực tế ổn định
- Kỳ vọng cao nhưng thực tế còn nhiều hạn chế
Điều cần làm:
- Tập trung vào bản chất hơn là hình thức
- Phát triển hệ thống kiểm soát hành vi AI
- Cân bằng giữa tự động hóa và sự kiểm soát của con người
🔮 Kết luận: AI thông minh thực sự là gì?
Không phải là "siêu trí tuệ"
AI thông minh thực sự không phải là hệ thống có thể giải quyết mọi vấn đề hoàn hảo. Thay vào đó, đó là hệ thống:
Biết giới hạn của mình:
- Thừa nhận khi không biết
- Không đưa ra kết luận vội vàng
- Biết khi nào cần sự trợ giúp
Cân bằng giữa suy nghĩ và hành động:
- Không "overthink" không cần thiết
- Không hành động thiếu căn cứ
- Tìm được điểm cân bằng phù hợp
Thích ứng với ngữ cảnh:
- Hiểu được yêu cầu cụ thể của từng tình huống
- Điều chỉnh cách thức hoạt động cho phù hợp
- Học hỏi từ phản hồi của môi trường
Thông điệp cuối
Chúng ta không cần những tác tử AI "giỏi lý luận suông". Chúng ta cần những tác tử AI biết khi nào nên nghĩ, và khi nào phải làm.
Hành trình phát triển AI thực sự hữu ích vẫn còn dài, nhưng cực kỳ thú vị. Thay vì bị choáng ngợp bởi các con số benchmark hoặc demo marketing, hãy tập trung vào việc xây dựng các hệ thống AI có thể hoạt động ổn định và hữu ích trong thế giới thực.
Tương lai của AI không nằm ở việc tạo ra "siêu trí tuệ" hoàn hảo, mà ở việc tạo ra những "cộng sự AI" thông minh, đáng tin cậy và biết cách cộng tác hiệu quả với con người.


